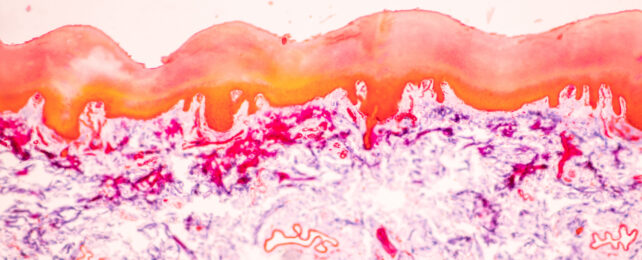
Environment52 mins ago 24% of Traceable Plastic Pollution Linked to Just 5 Corporations It highlights a need for accountability.
Most Precise Measure Ever Brings Us Closer to Knowing The 'Ghost' Particle's True Mass Physics2 days ago